SQL 2012 & High Availability IT Disaster Recovery in Azure

One of the biggest lures to Azure right now is for backup and disaster recovery (BDR). There are a number of ways that this can be implemented, including Azure Site Recovery and Azure Backup; however, when we look at options for SQL Server, we can really start getting into the business continuity aspect of BDR, with the potential for zero downtime in the event of a catastrophic failure. We’ll take a look at how we can put that in place and how Azure can be a key component.
Since the release SQL 2012, we have had the option of creating Highly Available (HA) AlwaysOn clusters when using the Enterprise Edition of SQL Server. With AlwaysOn, each SQL server is set up with its own set of data and changes are replicated real-time. In this configuration, all but one of the SQL servers in the AlwaysOn cluster can be lost and data accessibility will continue. At the time this was a big change from traditional clustering where there was a single source of data with multiple SQL servers, making the data the single point of failure.
One important thing to understand about AlwaysOn is that read/write access only happens on the server designated as the Primary. This is not a distributed transaction model, you cannot use the Secondary servers to uptake additional load, with one exception. Secondary servers can be tasked in a read only mode, allowing reporting, data extracts and the like to pull data from any of the secondary machines, freeing the primary server from this demand. From a licensing perspective, the secondary servers do not need to be licensed unless they are being used in a read only capacity.
Setting up an HA group is relatively easy and has a wizard that can be run from within management studio. There will need to be at least two servers, however more than two is a common and valid configuration. Servers can be added and removed from the cluster at will, so it is not necessary to start with your end-goal configuration. Other than the Enterprise edition of SQL, the only other components really needed are Windows clustering and to have a listener IP address configured. The listener is really what directs the traffic to the primary server, so a failover can take place and applications do not need to be updated to point to a new server, the listener handles the redirection automatically. The listener can also be used to direct the read-only traffic to a secondary server as long as the application has the ability to set the query intent to read only. This is known as a read-intent connection request. If this is not set, the listener will direct the request to the primary server. If the application cannot send a read-intent connection request, it can be pointed directly at a secondary server, but there would be no automatic failover in this case.
Once the Window’s failover clustering is in place, SQL server needs to be configured to allow an HA group. This is done in the SQL Server Configuration tool. Right clicking on the SQL service and selecting properties will open up a window where it can be enabled.
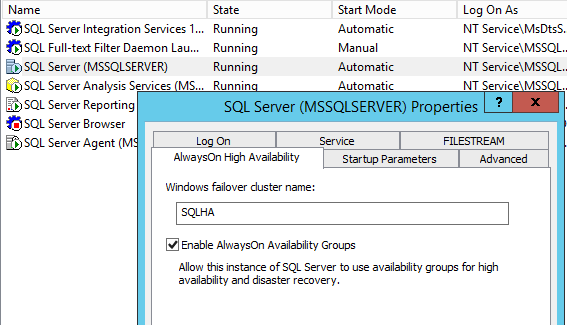
Once we have the ability to configure it, we need to plan the configuration of the AlwaysOn group since the physical location of the secondary servers is significant, but not limiting. They can be in the same data center or halfway around the world, including Azure. As long as there is a persistent network connection into Azure, an IaaS SQL Server could be provisioned as a secondary server. Similarly, in a scenario where the workload lives in Azure, an on premise server could be set up as a secondary, allowing local reporting to pull from the on premise server. Azure VPN tunnels can work for this connection, keeping in mind the Internet is in the way. Microsoft also offers ExpressRoute, a service that allows for a more direct and consistent connection from an on-promise data center into Azure.
Where location becomes significant is in the latency of the SQL commit. When configuring AlwaysOn cluster nodes, you have to configure either synchronous or asynchronous commit configurations. Synchronous ensures that data remains consistent among the servers as the commit on the primary does not occur unless it hears back from the secondary server(s) that they have performed the commit. While ensuring data integrity, this will also inject a delay. The greater the distance between the primary and secondary servers, the greater the delay. For servers in the same data center this is negligible and can be ignored. For servers sending updates across the internet this will lead to performance degradation. The fix is to configure the commit to be asynchronous.
When asynchronous commit is used, the primary server sends out an update and does not wait for a reply. This means that to SQL Server the data on the secondary is in an unknown state. This has a direct impact on failovers since when a server is in asynchronous commit mode, SQL will not automatically failover to that secondary. It can still be failed over to; it just becomes a manual process as a person has to decide if the data is in a consistent state or not. Fortunately, it is possible to have mixed commit modes between secondary servers. For example, the secondary that is connected across ExpressRoute to an Azure region in the same State as the primary server may have a fast enough connection that it could be used in a synchronous commit. A different secondary, connected via VPN and on the other side of the continent for geo-redundancy, would have to be in asynchronous. Both of these secondary servers could be connected in the same AlwaysOn group, providing the flexibility needed to handle almost any DR scenario.
Once we have our configuration planned out, we can start the setup wizard. Simply open SSMS and expand the AlwaysOn High Availability branch. Right clicking on the Groups will allow you to start the wizard.
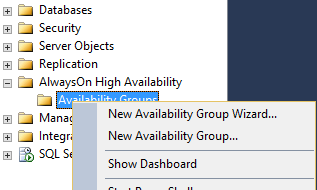
AlwaysOn must be set up at the server level, however the choice around what is replicated is done at the database level. It is possible to have two databases running on a server designated as a primary, but only have one of the databases be part of an availability group. This is actually a desired state for temporary databases or databases that are not needed for BDR. Ultimately, it is up to the business as to what needs replication. The only effect of replicating more databases is a slight overhead for monitoring and synching and additional space. All the servers in an availability group need to be able to store the full database/log files and need to have the same default configuration for database file locations. The servers themselves can be different specs, as long as they can handle the load required of them.
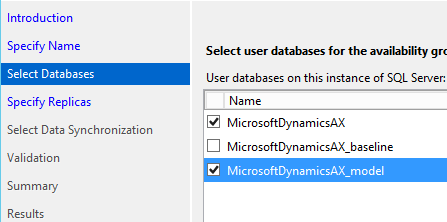
Note that there will be a check on the database state to make sure it is available for replication. It will have to have had at least one full backup, the wizard will specify what (if anything) needs to be done to begin replication.
With the databases selected, the final step before beginning replication is to select the destinations. By default the server the wizard is run on will be added to the cluster. Adding additional servers is done right in the wizard, as is setting the replication parameters.
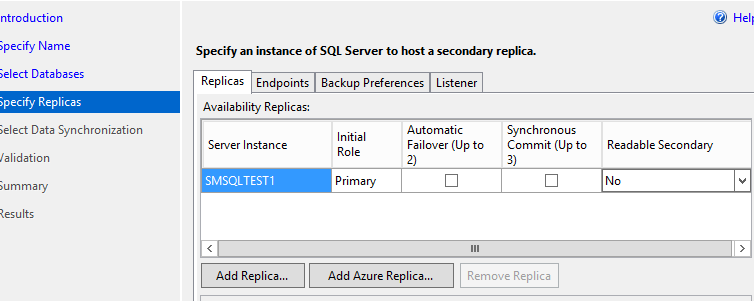
To have a server setup for automatic failover it must be configured for synchronous commit. Leaving all the boxes unchecked will leave the server configured for asynchronous commit. It is not required to have automatic failover configured, in the case of a failure on the primary node, manual intervention would be required. Note the setting for readable secondary. If that is set to false, the server will only be used for replication and the listener will not be able to send read-intent queries to it.
The final two considerations in an Azure connected AlwaysOn configuration are monitoring and security. Management and monitoring should work seamlessly with a VPN or ExpressRoute in place. Any monitoring or management tool that is currently touching local servers can be extended to run in Azure, making it appear as just another node or site. From an operational perspective this means that the additional servers simply join in on the existing method of operation. Latency may need to be considered, for example in ping tests that monitor network uptime, but once that is adjusted for, everything will work as if the resources were on premise.
Security, often a heated topic around cloud deployments, can be extended using either an IaaS VM configured to be a DC set up as a remote site across the VPN/ExpressRoute, or by using Azure Active Directory. This seamless integration allows for strict security control and single sign on capabilities making the final solution almost completely transparent to the end user. Having a VPN/ExpressRoute in place will also enable companies to direct their Azure communication across a protected connection allowing them to limit the need for direct internet access for servers that do not need to be public facing.
So now that we understand what SQL AlwaysOn can do and how we can leverage Azure to take advantage of it, let’s look at a specific case.
A company headquartered in Minnesota has branches in seven different states. The main financial application is considered a legacy application since it is not web based and it is accessed via terminal servers located in the headquarters’ data center. The data center has redundant power but only a single high speed Internet connection. The application uses SQL server and it has already been configured in an AlwaysOn HA group. Both SQL servers reside in the local data center, so are configured with synchronous commit. The total server count supporting the app is 10 – broken down into 3 application servers, 2 batch servers, 2 SQL servers and 3 terminal servers.
With this setup, the main exposure to downtime is the single Internet pipe, however the company has experienced a few unexpected downtime occurrences based on networking issues in their data center. The risk, they have decided, of having no one be able to process anything due to a failure in the main data center is too great and so they are looking at options.
Azure appears to be a great fit, but the company is hesitant to invest the time and resources to move the entire legacy app at once into an unknown environment. When they dig a little deeper into what Azure can do, they decide that having Azure be the BDR site would actually work out really well as the machines they provision would not need to be running unless they were needed. Having Azure be the cold spare would require some time to switch over to, but they calculate their exposure would be no more than an hour and that is determined to be acceptable.
When engineering the solution, the architects determine the following information: The application hardly ever changes, so the need to update the Azure application VMs would be minimal. The current infrastructure is designed to handle peak load during year end, however for most of the time, the demand is about ¼ of what is supported. Finally, although an hour of downtime is acceptable, replicating their database – which is currently 300 GB compressed, would take far longer than that, assuming it was even available to replicate.
By simply creating an Azure VPN, standing up a SQL VM and joining it to their existing AlwaysOn cluster, the company has removed the dependency on their data center for access to the data. Due to the latency of the VPN connection, the Azure SQL Server will be configured in asynchronous commit, requiring a manual failover, however they will need to do manual work to get the application failed over anyway.
The last piece of the configuration will be to allow their branches to continue processing, which means the application will need to be made available in Azure as well. Since the company has decided this scenario will be to mitigate a critical failure, the batch servers are deemed optional as they can survive a day or two processing what they need to manually. Similarly, a single application server and a single terminal server can support the typical demand, which is ¼ peak demand. Even if it is a bit slow, at least they will be able to process. Using the Azure VM import tools, they actually copy two of their existing VMs into Azure, and with a few networking changes, they are ready to use.
So the final Azure configuration consists of a SQL server that will be left running all the time to accept data updates, one application server and one terminal server, both of which will be left off, costing virtually nothing until they are needed.
In the case of a data center outage, company engineers can simply start up the two VMs – which would already be configured to use the SQL server listener – and perform a manual SQL failover. Users would connect to a different terminal server; however even this could even be hidden by a quick DNS change. After a brief outage, the users continue their work as if nothing has happened.
When the data center issue is resolved and the on-site SQL servers are available again, they will come back in secondary mode. After ensuring the data has been correctly synchronized back down from Azure, the company can switch back to having the primary on-site and resume using the onsite terminal servers. The SQL server in Azure switches back to secondary mode and the app and terminal servers can be shut down again.
This example may seem over simplified, however there are tools in Azure that would allow for continuous VM updates and automatic failover as well. The actual setup can and will be as varied as the companies that require them.
One additional benefit of operating this way is that if the company does decide they want to move their application fully into Azure and have their onsite be the BDR location, the main operations are already configured and there will be very little time required to switch over.
Microsoft has really put some thought into the design of SQL AlwaysOn and now provides companies with a very robust replication system. When coupled with the simplicity of Azure, almost any BDR requirements can be met. Only requiring a few additional hours of setup and the licensing impact being minimal (when the secondary servers are not put into rotation as read only access points), even small companies that traditionally struggle with BDR justifications should be able to find a solution that fits their needs.


